네이버 카페 게시글 일괄 스크래핑 하기
수 천개의 네이버 카페 게시글을 한 번에 스크래핑하는 자동화 시스템을 구축할 수 있어요.

이런 분들께 추천합니다.
- 챗봇(LLM) 데이터 확보를 위해 스크래핑이 필요한 기업.
- 지역/분야 트렌드 파악을 필요로 하는 마케터
준비물 📋
- 접근하고자 하는 네이버 카페 게시판에 접근할 수 있는 계정 (등업 등)
- 결과 데이터를 저장할 구글 시트
📖 방법
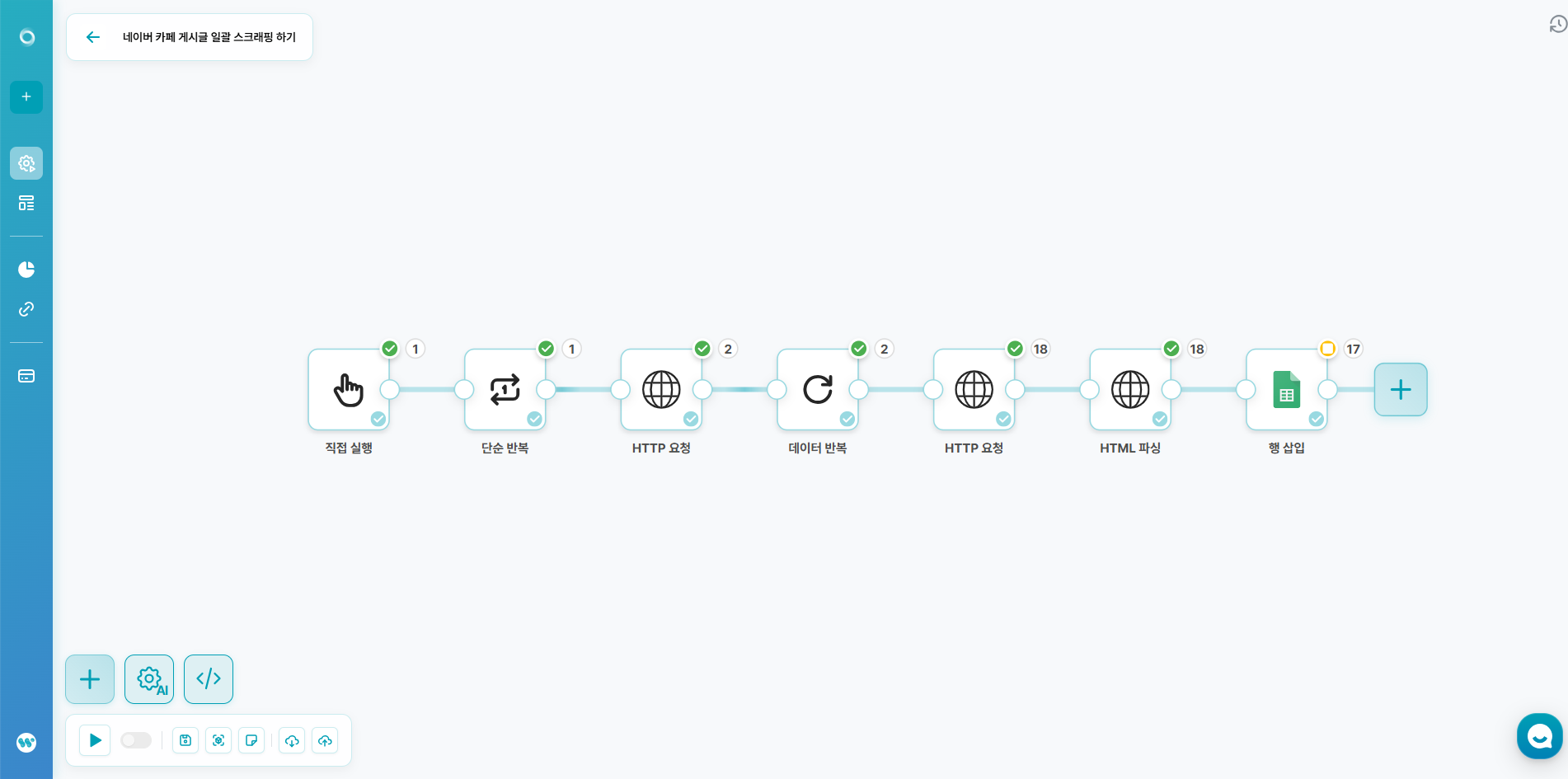
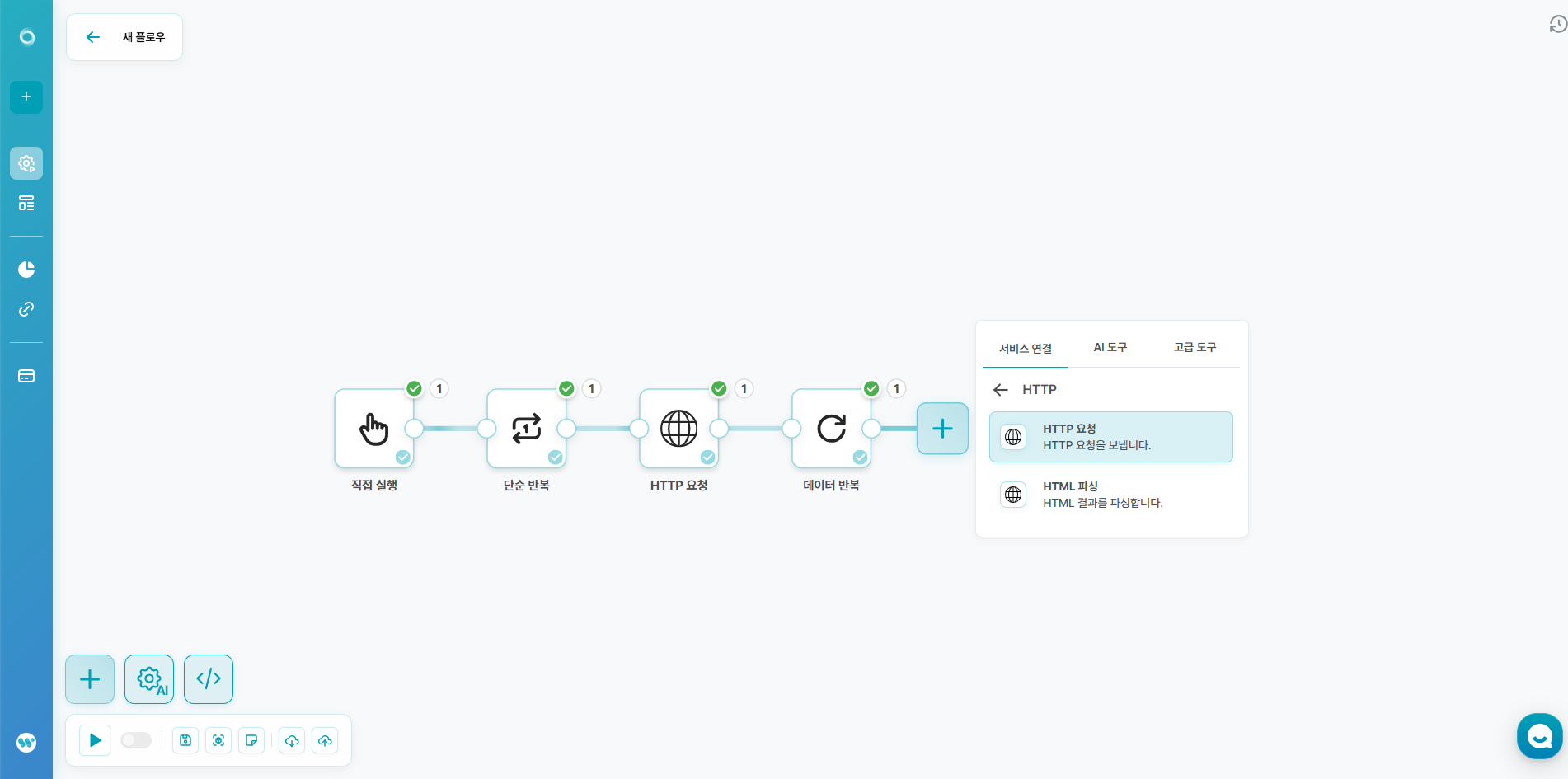
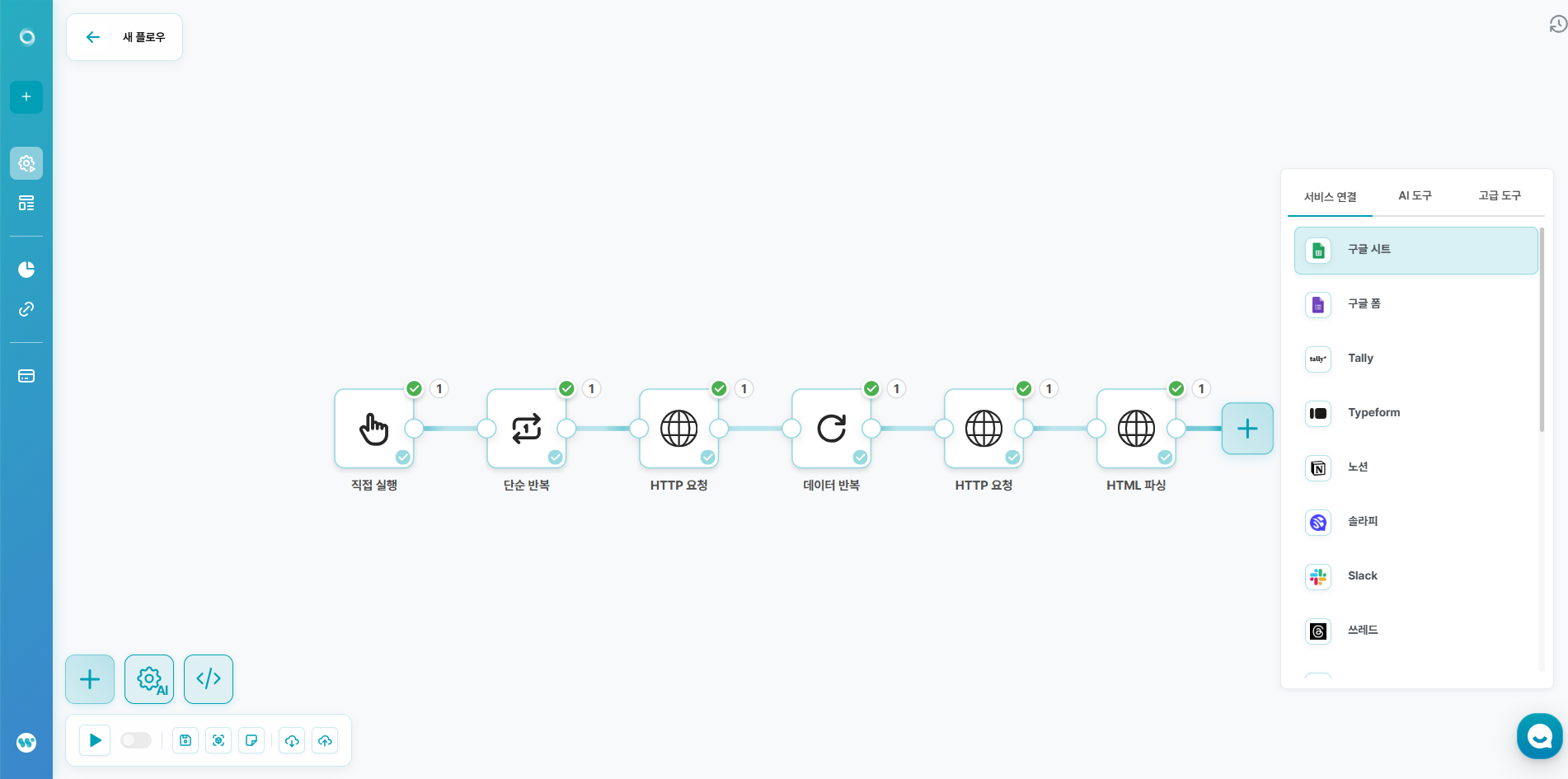
1️⃣ 자동화 플로우 생성
- 스니핏 서비스로 접속해주세요. 주소: https://snipit.im
- 계정이 없는 경우, 회원가입이 필요해요.
- 로그인 후, 플로우 추가를 클릭해주세요.

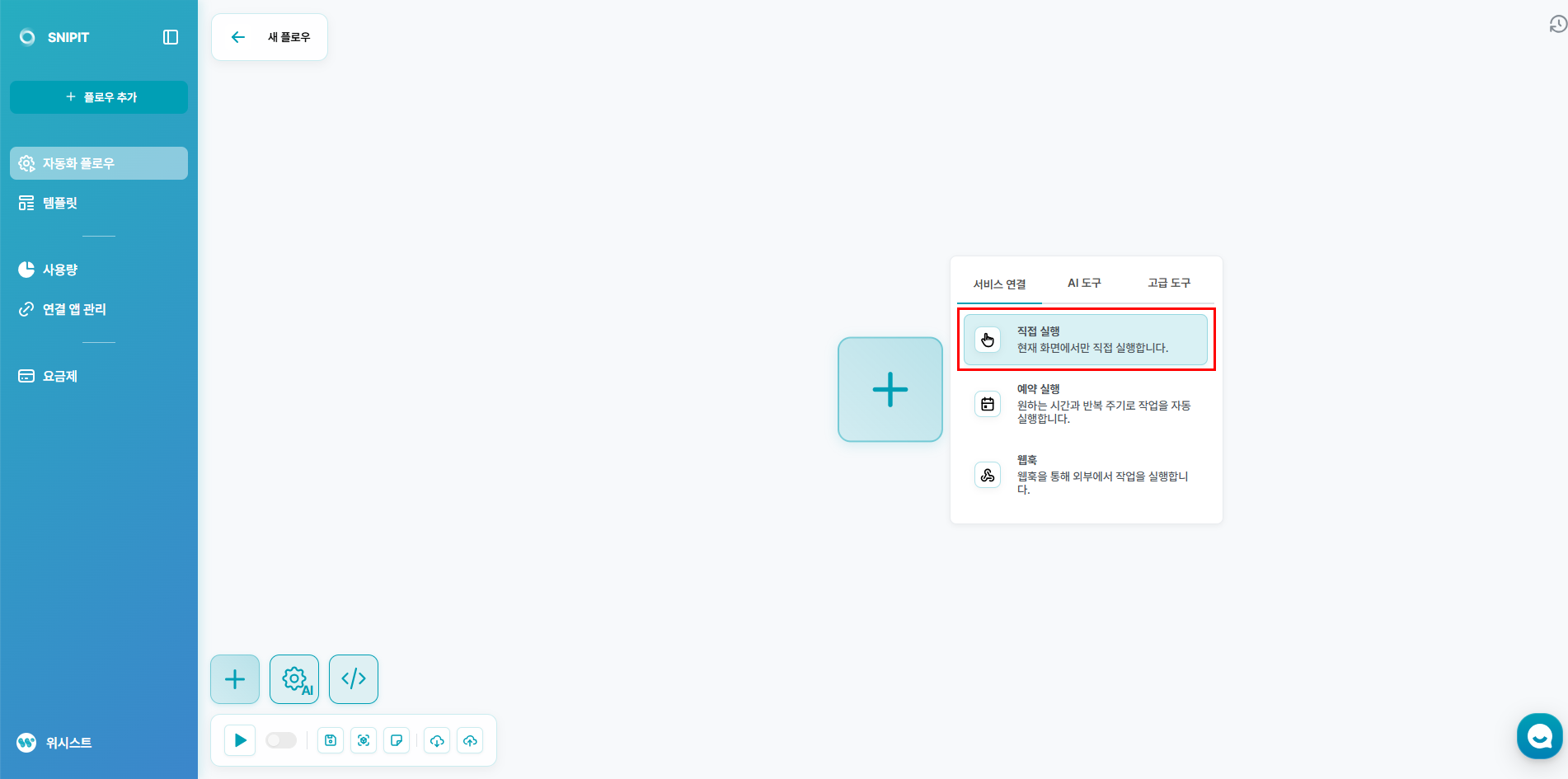
2️⃣ 시작 조건 설정
- 데이터를 한 번에 일괄적으로 가져오기 위한 것이기 때문에, 직접 시스템을 실행하는 '직접 실행' 을 선택해주세요.
3️⃣ 단순 반복 설정
- 단순 반복은 1부터 반복 횟수까지 1씩 증가하며 연결된 플로우를 실행되는 노드입니다. (고급 도구 - 단순 반복)
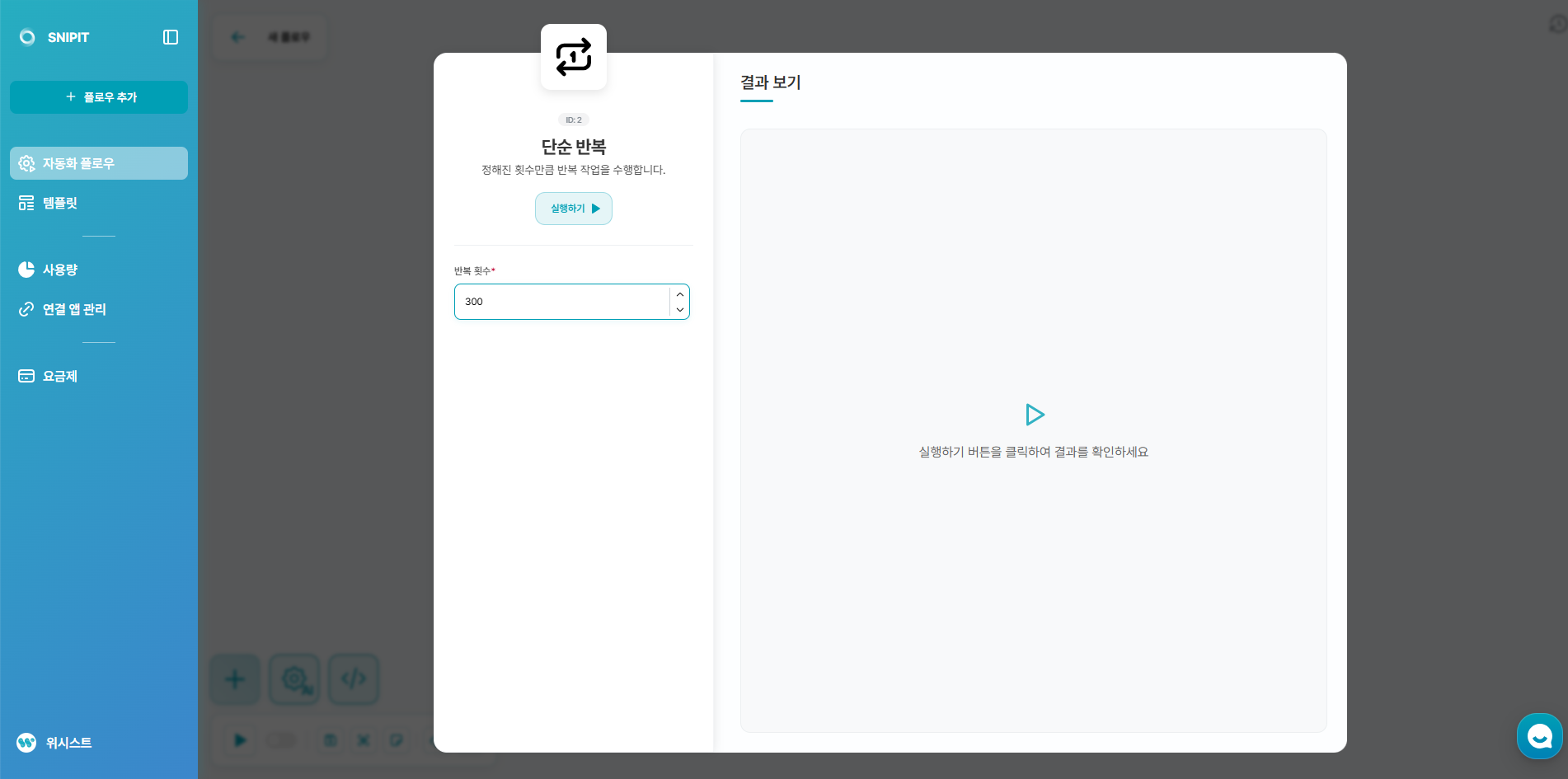
- 최대로 가져올 페이지 수를 반복 횟수로 설정해주세요.
4️⃣ 게시글 목록 가져오기
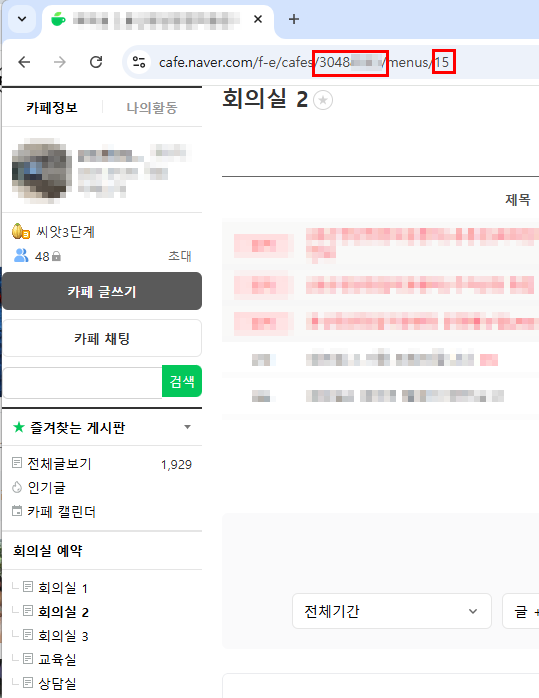
- 네이버 카페 게시글 목록을 가져오기 위해, 카페 ID와 게시판 ID가 필요합니다. 데이터를 가져올 카페 게시판에 들어가셔서 주소를 확인해주세요.
아래의 경우, 3048xxxx 가 카페 ID, 15가 게시판 ID 입니다.
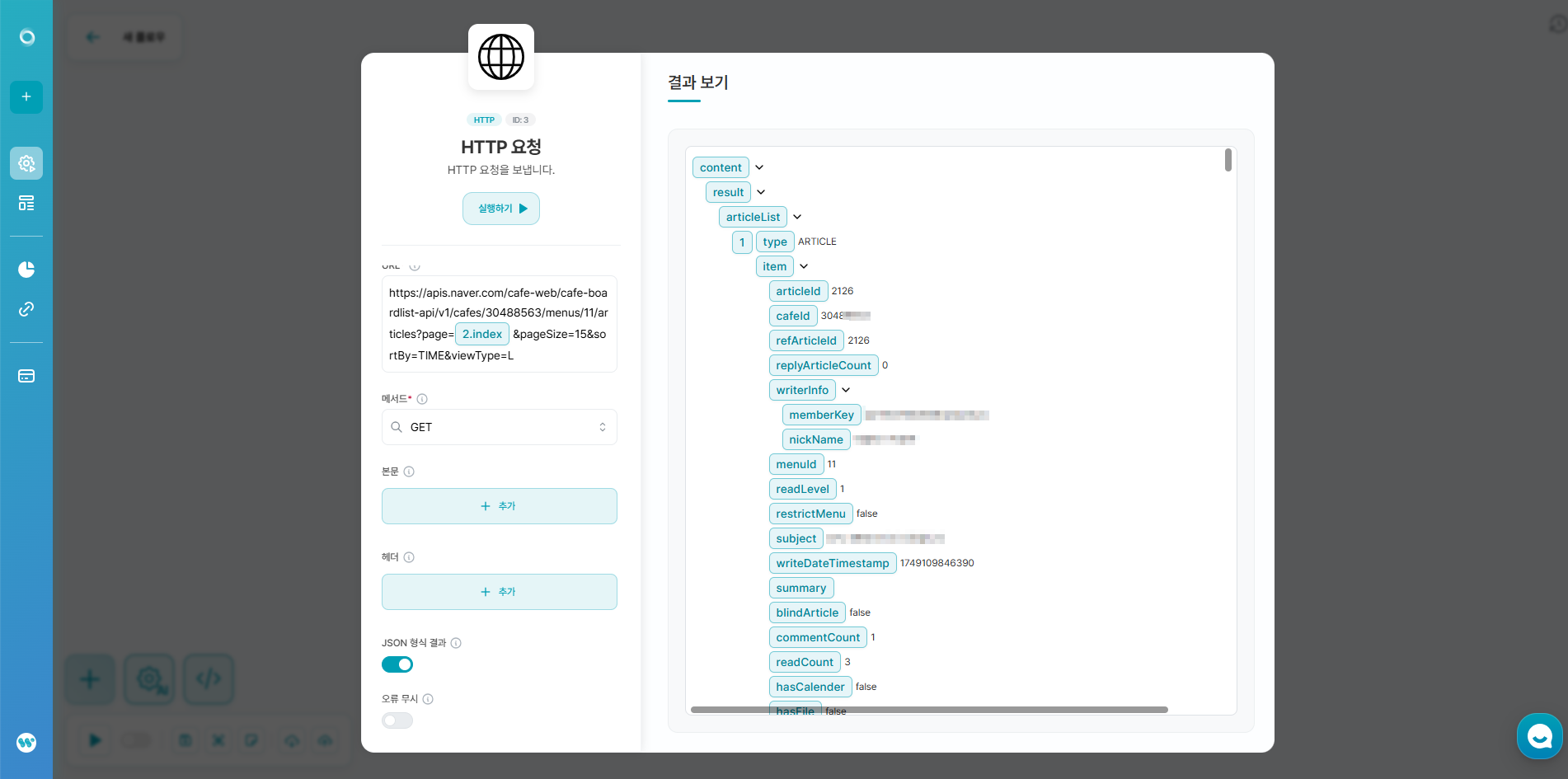
- 서비스 연결 - HTTP - HTTP 요청을 생성해주세요.
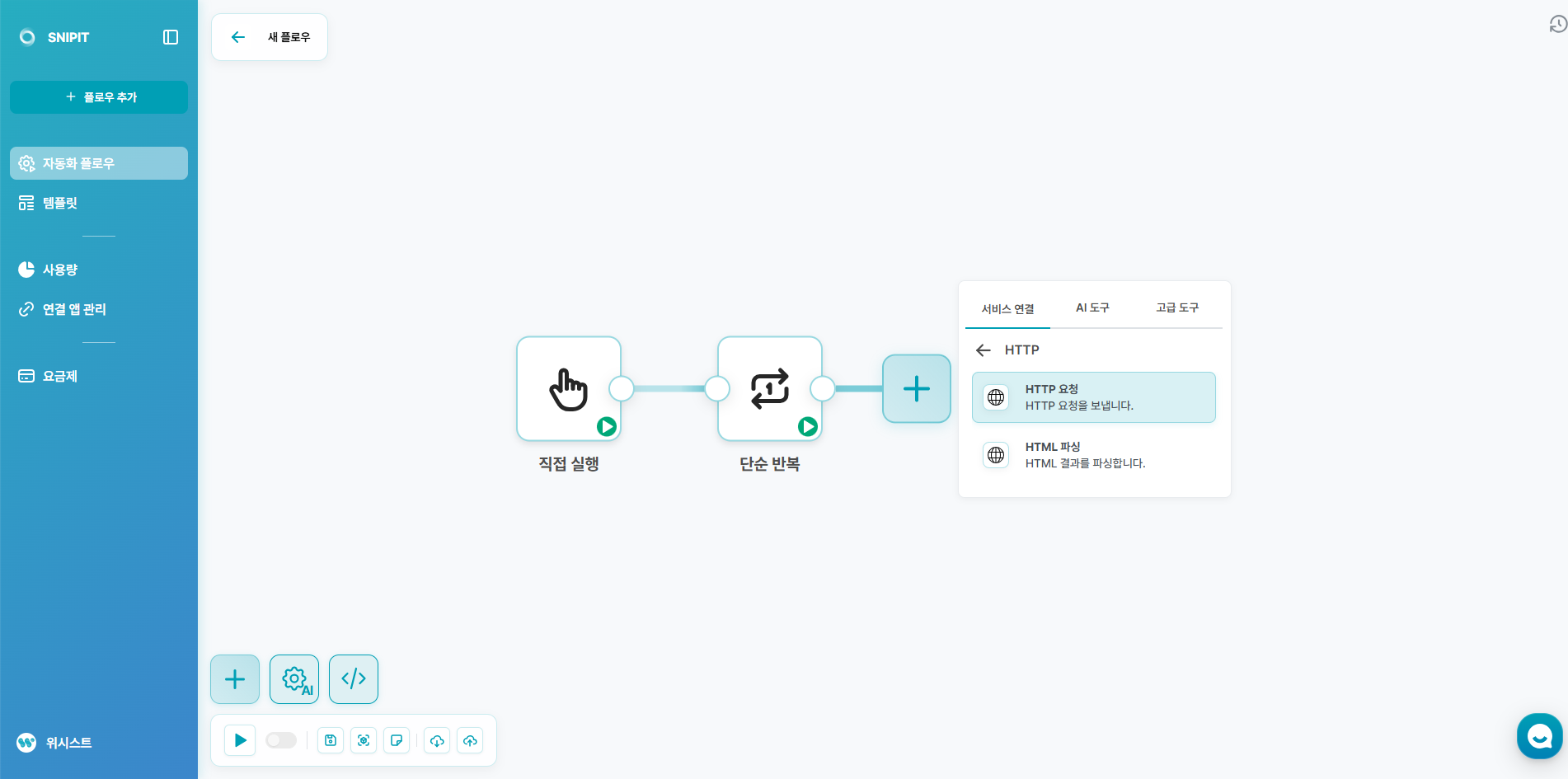
- 다음의 내용을 입력해주세요.
- URL:
- https://apis.naver.com/cafe-web/cafe-boardlist-api/v1/cafes/카페ID/menus/게시판ID/articles?page=1&pageSize=15&sortBy=TIME&viewType=L
- 카페 ID와 게시판 ID는 위에서 확인한 값으로 변경해주세요.
- page=1 대신, 단순 반복 노드의 'index'정보를 활용해주세요.
- 메서드
- GET
- JSON 형식 결과
- 켜기
- 작성 예시
5️⃣ 게시글 하나씩 나누기
- 고급 도구 - 데이터 반복을 생성해주세요.

- 데이터 반복 - 배열에 이전 HTTP 요청 노드의 content.result.articleList를 연결해주세요.

6️⃣ 게시글 본문 정보 가져오기
- 본문 정보를 가져오기 위해서는, 네이버 로그인 시 생성되는 정보(쿠키 정보)가 필요합니다.
- 네이버 로그인 후, 스크래핑할 카페로 접속해주세요.
- F12(관리자도구) - 네트워크를 선택해주세요.
- 'NNB'를 검색해, 검색 결과를 클릭해주세요.
- 아래 사진과 같이 Cookie 전체를 복사해주세요.

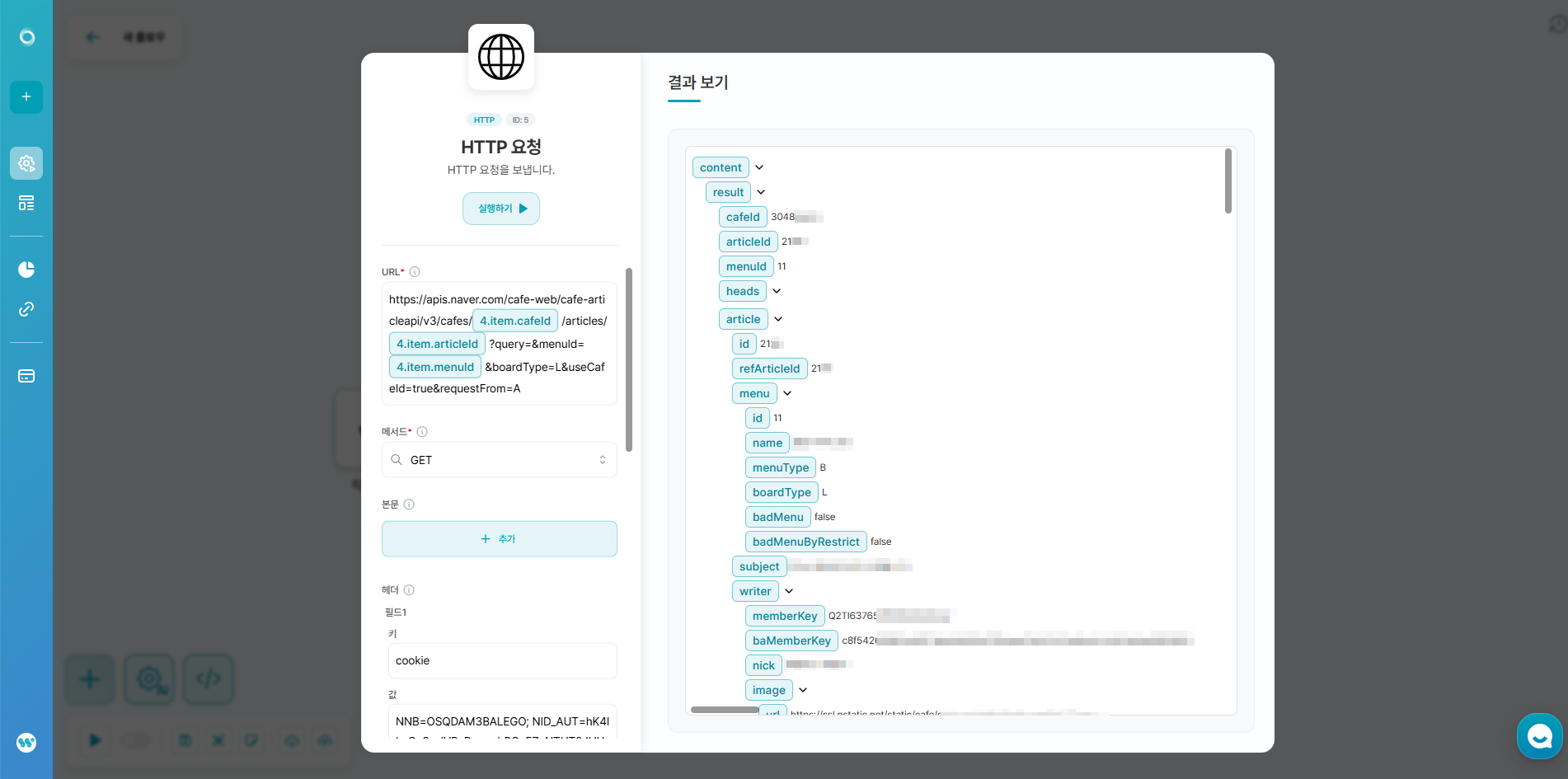
- 서비스 연결 - HTTP - HTTP 요청을 생성해주세요.
- 위에서 가져온 쿠키를 활용해 아래와 같이 작성해주세요.
- URL:
- https://apis.naver.com/cafe-web/cafe-articleapi/v3/cafes/{{카페ID}}/articles/{{게시글ID}}?query=&menuId={{게시판ID}}&boardType=L&useCafeId=true&requestFrom=A
- {{카페 ID}}, {{게시글ID}}, {{게시판 ID}}는 데이터반복에서 해당하는 값을 찾아서 연결해주세요.
- {{카페ID}}: item.cafeId
- {{게시글ID}}: item.articleId
- {{게시판ID}}: item.menuId
- 메서드
- GET:
- 헤더: 추가 버튼을 클릭한 후 다음과 같이 입력해주세요.
- 필드1
- 키: cookie
- 값: 위에서 가져온 쿠키 정보
- 필드1
- URL:
- JSON 형식 결과
- 켜기
- 작성 예시
7️⃣ 게시글 본문 정보 추출하기
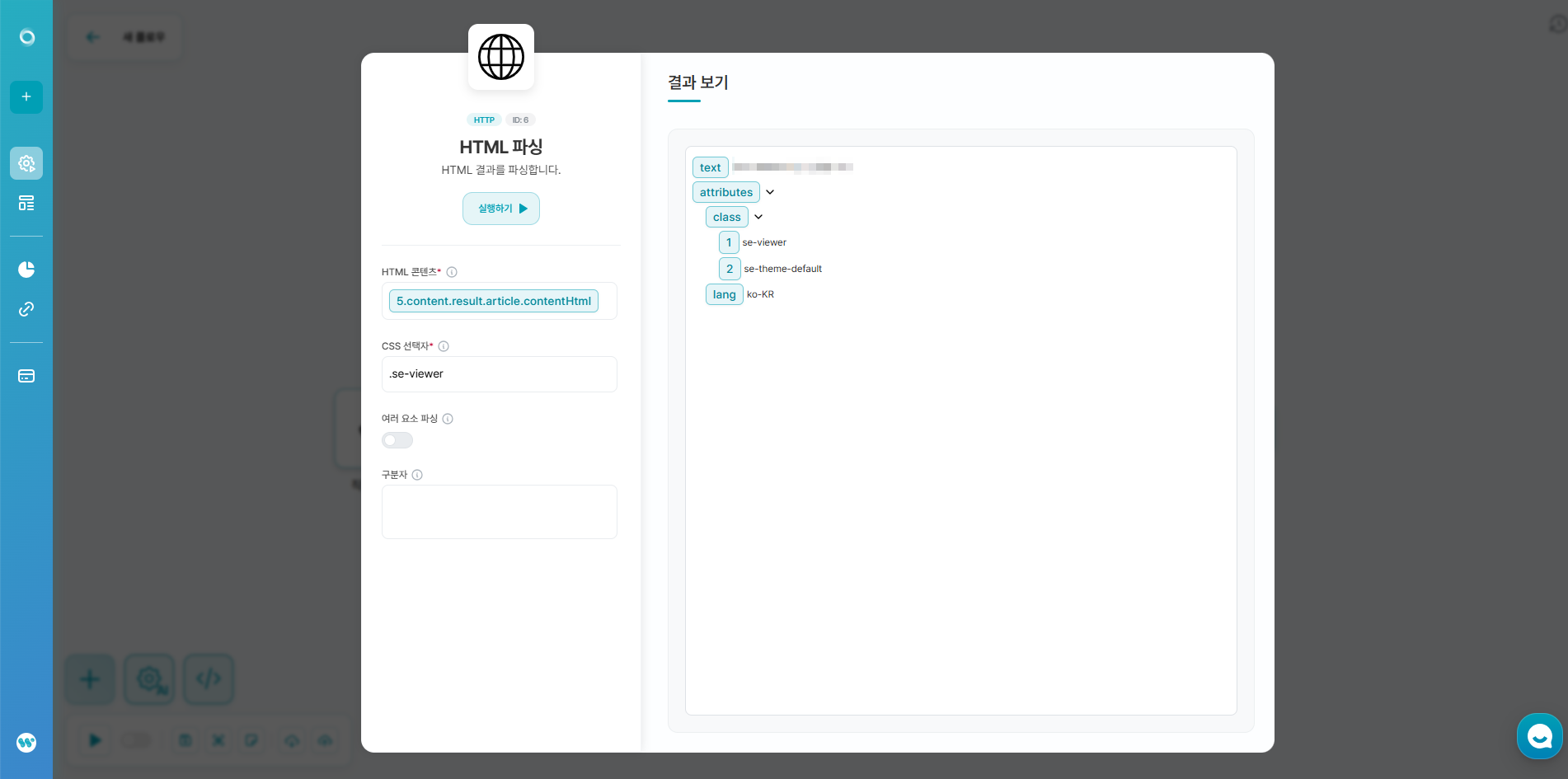
- 서비스 연결 - HTTP - HTML 파싱을 생성해주세요.
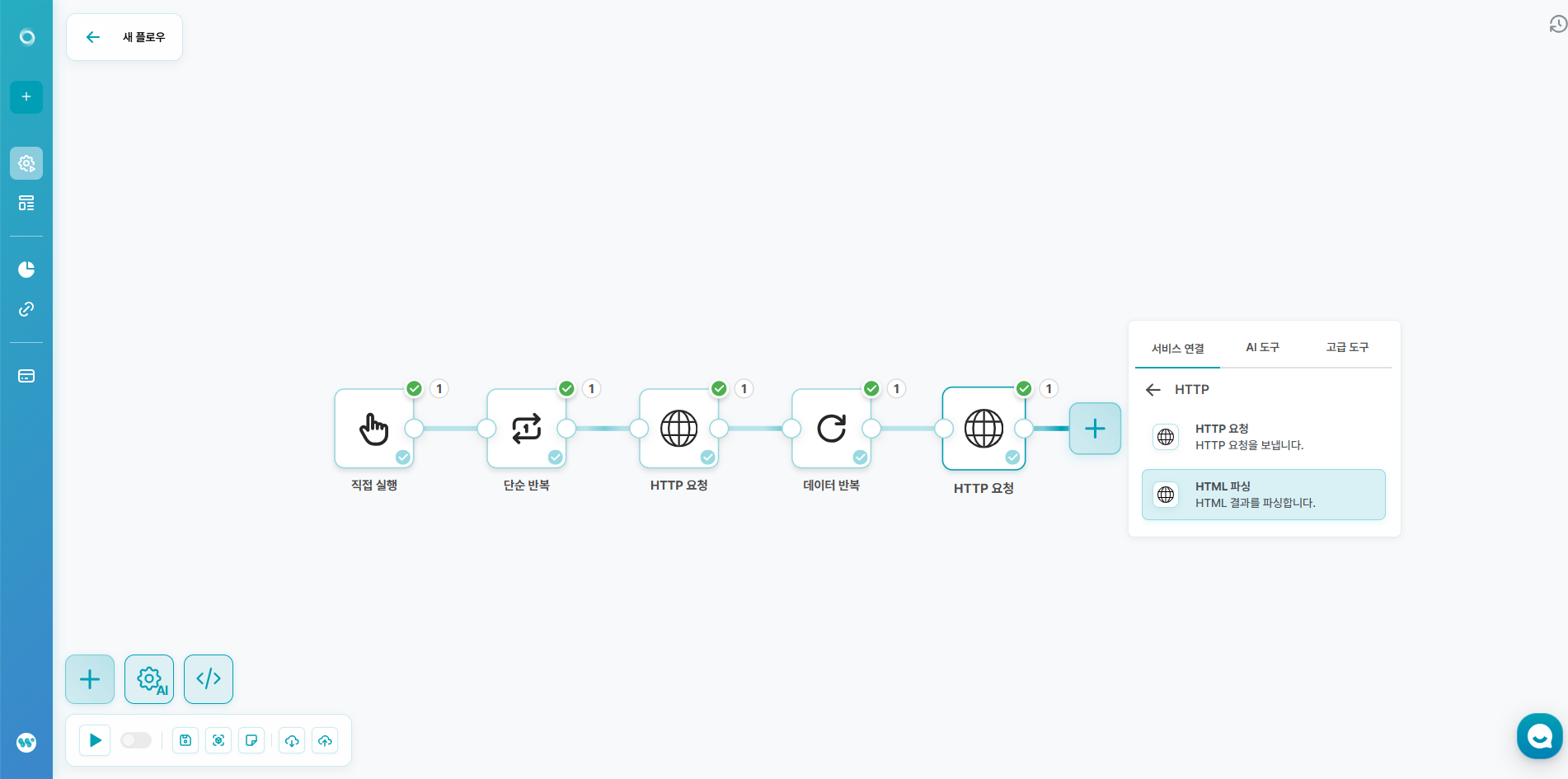
- 다음과 같이 설정해주세요.
- HTML 콘텐츠
- 이전 HTPT요청 노드의 content.result.article.contentHtml 연결.
- CSS 선택자
- .se-viewer
- HTML 콘텐츠
8️⃣ 데이터 저장하기
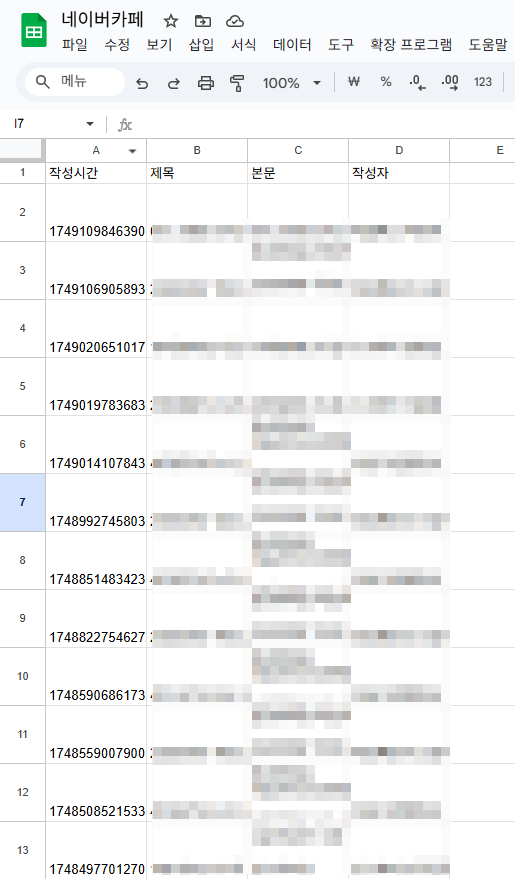
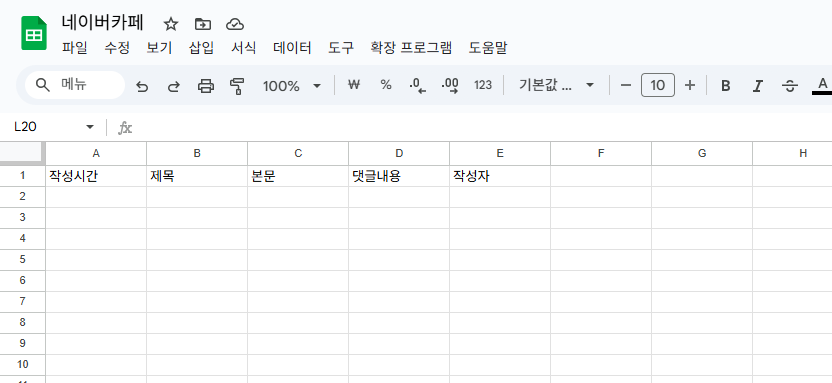
- 데이터를 저장할 구글 시트를 다음과 같이 생성해주세요. (아래는 예시입니다.)
- 서비스 연결 - 구글 시트 - 행 삽입을 생성해주세요.
- 다음과 같이 설정해주세요.
- 구글 시트 계정 연결
- 구글 시트를 생성한 구글 계정
- 스프레드 시트 선택
- 데이터를 저장할 구글 시트
- 시트 이름
- 데이터를 저장할 시트
- 입력 데이터 (필요한 데이터를 저장해보세요. 아래는 예시입니다.)
- 1열 (작성 시간)
- 게시글 불러오기 HTTP 요청의 content.result.article.writeData 연결
- 2열 (제목)
- 데이터 반복하기의 item.subject 연결
- 3열 (본문 내용)
- HTML 파싱의 text 연결
- 4열 (닉네임)
- 게시글 불러오기 HTTP 요청의 content.result.article.writer.nick 연
- 1열 (작성 시간)
- 구글 시트 계정 연결

9️⃣ 실행
- 왼쪽 아래의 실행 버튼을 클릭하면 네이버 카페 게시글이 구글 시트로 저장 됩니다.